
Introduction
Every business is a lot about analyzing and streamlining. The amount of information to be revised and maintained is increasing rapidly alongside the software development trends. When data management becomes an issue, there are quite a few methods to solve the problem, clustering being one of them.
So what is clustering? How does it work? What are the applications?
What is clustering?
Clustering is a statistical procedure of gathering and streamlining classified data for further analysis. Simply put, by diving your consumers into smaller classified groups, you can operate the statistical data much easier and come up with a more agile and accurate approach.
The clustering technique is a powerful tool for business scaling and general consumer analysis, meaning it can help you understand and thus fulfill the needs of your customers, as well as enhance the overall quality of your product.
Clustering types and algorithms
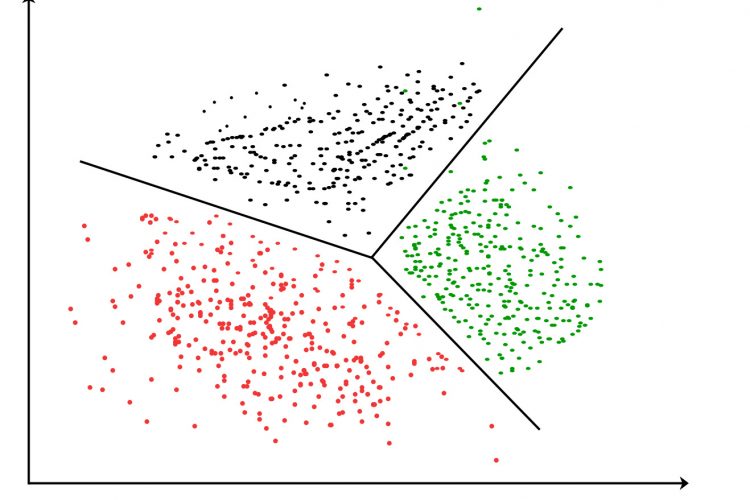
Generally speaking, clustering can be further classified as soft or hard based on the implied procedure.
Unlike hard clustering, where each entity of data has to belong to at least one of the groups, soft clustering assigns each entity a certain probability of getting into each of the aforementioned groups. You can use online whiteboard as a way to do clustering. Check it out and try it!
Clustering implies many algorithms, each adjusted to serve one or multiple purposes. The number of known clustering algorithms is nearing a hundred, the most popular of them being connectivity, centroid, density, and distribution models. Let’s take a brief look at these algorithms, so you could maybe settle on one model that would best suit your needs.
Connectivity models operate the data entities and the “distance” between them in the data space, thus connecting varying values based on how close they are to one another. The algorithm is fairly easy to comprehend, but its scalability is far from good.
Centroid models are conceptually close to connectivity, but the central point of distance calculation is a particular value rather than the data entities themselves.
Distribution models operate a probability, with which a data entity is about to belong to a distribution.
Density models operate the density of entities in a singular data space.
How do you use clustering?
Now that we’ve taken a glimpse at the main properties and types of clustering algorithms, we should once more point out the applications of clustering in various industries.
Clustering is a no-brainer in constructing advertisement engines for targeted marketing, analysis of social media, image segmentation, adjusting the searching systems, and detecting anomalies in vast datasets. That is not to mention how clustering possesses a handful of features, suitable for creating a supervised learning algorithm, which is potentially beneficial to make market predictions.
Each of these applications requires a different approach, which is why multiple algorithm models are a thing.
Conclusion
Clustering is a reliable tool for meticulous analysis, market predictions, and data management of variable scale. Clustering algorithms make business scaling easier, as well as increase the overall performance of the company. Thanks to the flexibility of clustering algorithms and models, each singular task can be optimized and performed flawlessly.